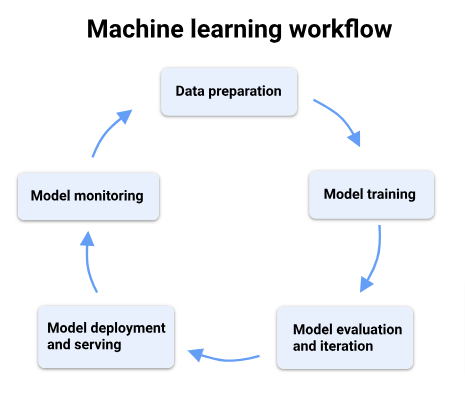
As datasets grow in size and complexity, so do the challenges associated with data preparation, including data cleaning, feature engineering, and transformation. Orchestrating data preparation is essential for scaling ML workflows, enabling ML practitioners to efficiently process large volumes of data and iterate on model development.
In this article, we’ll explore the importance of orchestrating data preparation, key strategies for scaling ML workflows, and practical considerations for implementation.
Understanding Data Preparation in ML Workflows
Data preparation is a critical step in ML workflows, where raw data is transformed into a format suitable for training ML models. This process involves several tasks, including:
Data Cleaning: Identifying and handling missing values, outliers, and inconsistencies in the data.
Feature Engineering: Creating new features or transforming existing features to improve model performance.
Data Transformation: Scaling, encoding, or normalizing data to ensure compatibility with ML algorithms.
Effective data preparation is essential for building accurate and robust ML models. However, as datasets grow in size and complexity, manual data preparation becomes increasingly time-consuming and error-prone.
What is the Need for Orchestrating Data Preparation?
Orchestrating data preparation is essential for scaling ML workflows for several reasons:
Efficiency: By automating data preparation tasks, ML practitioners can streamline the ML workflow, reducing the time and effort required to process large volumes of data.
Scalability: Orchestrating data preparation enables ML practitioners to scale their workflows to handle datasets of varying sizes and complexities.
Consistency: Automated data preparation ensures consistency across ML experiments, reducing the risk of errors and inconsistencies in model training.
Some Strategies for Scaling ML Workflows
Several strategies can be employed to orchestrate data preparation and scale ML workflows effectively:
Pipeline-based Approach: Adopting a pipeline-based approach to data preparation allows ML practitioners to define a sequence of data processing steps and execute them in a structured and automated manner. Tools such as Apache Airflow, Luigi, and Kubeflow provide frameworks for building and managing ML pipelines.
Parallel Processing: Leveraging parallel processing techniques enables ML practitioners to distribute data preparation tasks across multiple computing resources, reducing processing time and improving overall efficiency. Technologies such as Apache Spark and Dask offer distributed computing frameworks for scalable data processing.
Containerization: Containerization technologies such as Docker and Kubernetes provide lightweight and portable environments for running data preparation tasks. Containerization facilitates reproducibility and portability of ML workflows across different computing environments.
Practical Considerations for Implementation
When orchestrating data preparation, ML practitioners should consider the following practical considerations:
Data Pipeline Design: Designing an effective data pipeline requires careful consideration of data dependencies, processing steps, and error handling mechanisms. ML practitioners should strive to create modular and reusable pipeline components to promote code maintainability and scalability.
Resource Management: Efficient resource management is essential for scaling ML workflows. ML practitioners should monitor resource utilization, optimize task scheduling, and allocate computing resources dynamically based on workload demands.
Data Governance and Security: Ensuring data governance and security is paramount when orchestrating data preparation. ML practitioners should implement data access controls, encryption, and auditing mechanisms to protect sensitive data and comply with regulatory requirements.
Real-World Applications of Orchestrating Data Preparation
Orchestrating data preparation finds applications across various domains:
E-commerce: In e-commerce, orchestrating data preparation enables retailers to process large volumes of transaction data, analyze customer behavior, and personalize product recommendations at scale.
Healthcare: In healthcare, orchestrating data preparation facilitates the analysis of electronic health records (EHRs), medical imaging data, and genomic data for disease diagnosis, treatment planning, and clinical research.
Finance: In finance, orchestrating data preparation supports risk management, fraud detection, and algorithmic trading by processing market data, transaction logs, and customer transactions in real-time.
Orchestrating data preparation is essential for scaling ML workflows and enabling ML practitioners to efficiently process large volumes of data. By adopting pipeline-based approaches, leveraging parallel processing techniques, and embracing containerization technologies, ML practitioners can streamline data preparation tasks and accelerate model development.
As ML continues to evolve and become increasingly central to business operations, orchestrating data preparation will play a crucial role in driving innovation and unlocking the full potential of ML applications.